* The table shows the score under the Zero-Shot Setting.
- The GPT models were evaluated on 03/15/2024, which is slightly different from the paper.
- Additional results from other models will be included in the future.
Experimental Results Leaderboard on Textbook Dataset
SciBench Dataset
Overview
SciBench is a carefully curated dataset of college-level scientific problems, collected from widely-used textbooks in college-level Chemistry, Physics, and Mathematics courses. Distinct from existing benchmarks, all of the problems are open-ended, free-response questions that demand multi-step reasoning abilities, the understanding of scientific concepts, the retrieval of domain-specific knowledge (e.g., equations and theorems), and complex numeric computation capabilities (e.g., calculus or differential equations).
To evaluate the capabilities and analyze the limitations of Large Language Models (LLMs) to solve scientific computing problems, we collect a new dataset consisting of college-level textbooks and course exams in a variety of domains. This section details the dataset construction process.
Data selection criteria.Our dataset aims to improve the previous benchmarks by including more challenging problems. Specifically, the selected dataset should fulfill the following requirements:
- Inclusion of college-level problems.The chosen problems demand a solid understanding of domain-specific knowledge, adept calculation skills, and the ability to perform complex numerical computations.
- Inclusion of detailed solutions.To facilitate a thorough analysis of the limitations of LLMs, detailed solutions should be provided as well, which could facilitate a finergrained examination of the capacity of LLMs to handle complex problem-solving tasks.
- Inclusion of visual elements.In real-world, many scientific problems require the interpretation and integration of both textual and visual information. The included problems should thus contain visual elements (such as figures) in the contexts.
- Inaccessibility in text formats.To ensure an unbiased evaluation, questions should not be readily accessible online and cannot be easily extracted or transformed into text. This aims to mitigate any potential information leakage from the exposure of LLMs to pre-existing online question banks, such as those found in standardized tests like the SAT exams.
- Assessment of advanced problem-solving capabilities.The problems to benchmark should not be confined to basic arithmetic operations like addition and multiplication. Rather, they should enable evaluating the capability of LLMs in performing advanced computations such as calculus and differential equations.
Examples
One example for each textbook from SciBench

fund textbook

thermo textbook

class textbook

quan textbook

chemmc textbook

atkins textbook

matter textbook

calc textbook

stat textbook

diff textbook
One example in visual context from SciBench
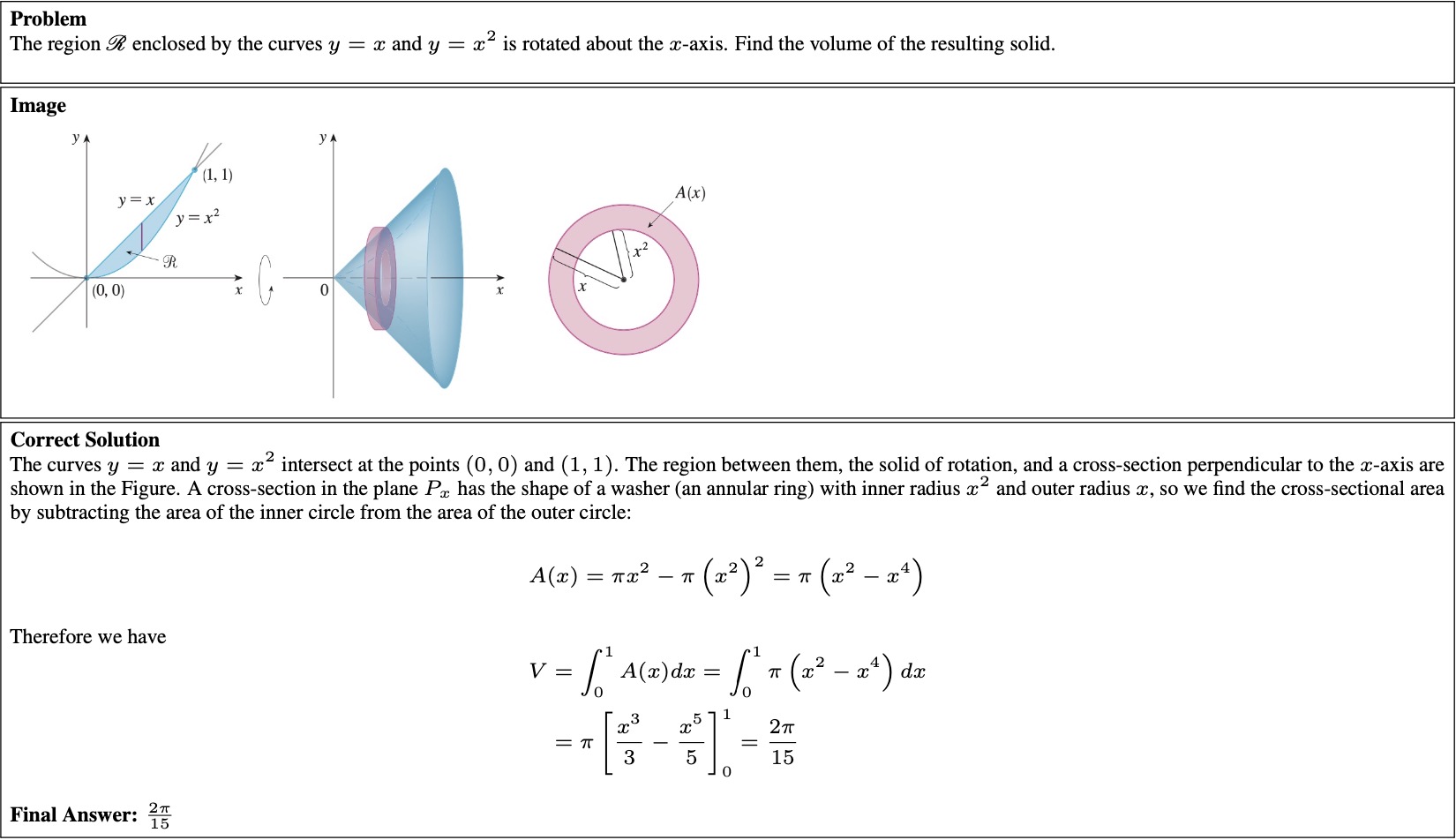
calculus textbook

fund textbook


